RefEntry Client Design
This chapter covers client architecture and describes the user interface both for the browser based client and for the documentation tools.
WebMan Client Viewer
On the client side, only a browser capable of reading XHTML is required. The XHTML used must fit as much as possible the behavior of existing browsers. Empty tags such as <elementĀ/> must include the space for this to work well with older browsers.
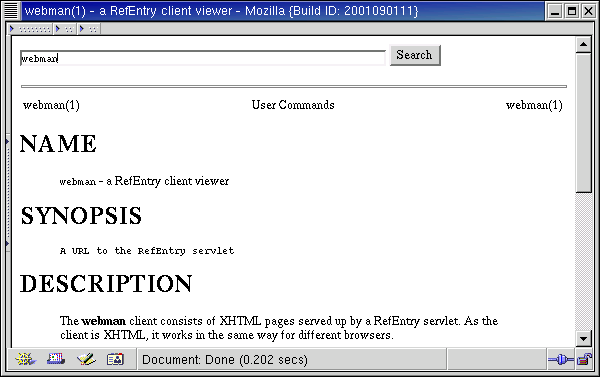
The default client page is the RefEntry for the client browser itself. At the top of each webman page, a search bar allows the reader to enter a search string used by the servlet to find corresponding RefEntry pages. The servlet displays different webman pages, depending on the results of a search. This interface should be usable both in graphical user interface browsers, and in command-line user interface browsers. The command-line version should enable accessibility technologies such as text-to-speech or braille interfaces.
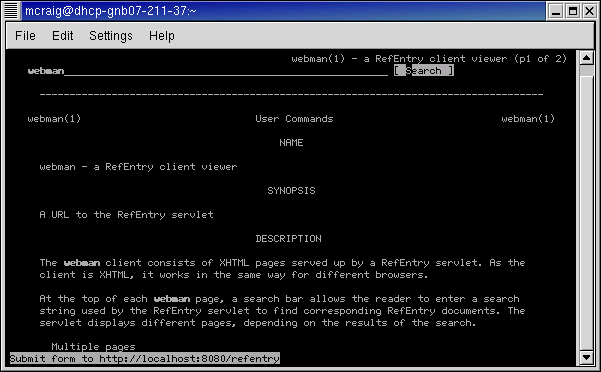
The XHTML itself should be accessible, such that it is easy to read without a graphical user interface.
The search interface works only for keyword searches, returning a union of everything found. This results in more search hits than desired in many cases, meaning the algorithm is not very useful for a large number of RefEntry documents. Implementing a more effective algorithm is something to be done in a subsequent version of the project.
When a search turns up more than one result, the client shows the RefName and RefPurpose for each result, allowing the user to select a further page.
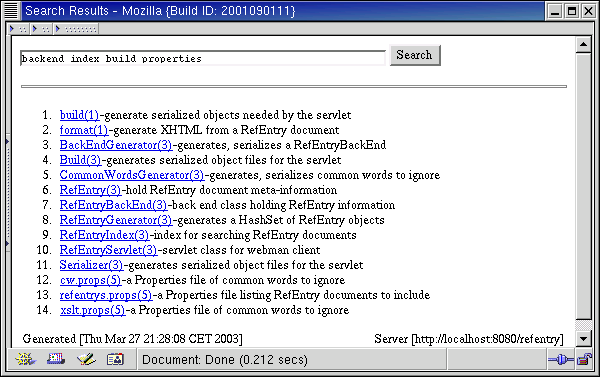
The search results are always returned in the search area of the client page, so the user can easily refine a search based on what has already been typed.
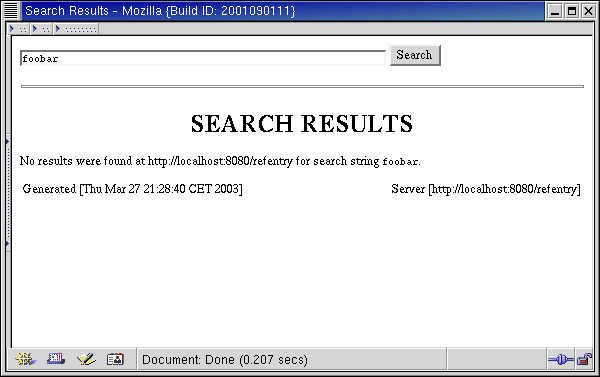
If a particular search turns up no results at all, the page in the preceding figure is returned.